Content analysis of YouTube comments on Zuckerberg's congressional hearing
Noting the complete reliance of this project on computational methods, this post details steps taken in working with more traditional forms of content analysis. Staying with the theme of the Facebook and Cambridge Analytica scandal it looks at comments made on YouTube in response to Mark Zuckerberg’s Live hearing with congress.
Approach
Pretext
Having learnt about computer programming before more traditional content analysis, I hadn’t taken that much of an interest in it. Systematically processing media in accordance with a specific set of instructions sounds a lot like the work of machines. Not only that the interpretability of such ‘code books’ is a lot more subjective than a computer executing source code. However, after recently reading serval essays on the subject, interest was sparked in investigating its utilisation in a manner that combines the capacities of human and machine labour effectively. Zamith and Lewis (2015) provided comparisons between algorithmic and human approaches to coding data which informed strategies. The work of Graham (2008) was used as a starting point for an investigation of civic discussions online whilst branching off into their citations for further reference.
Investigation
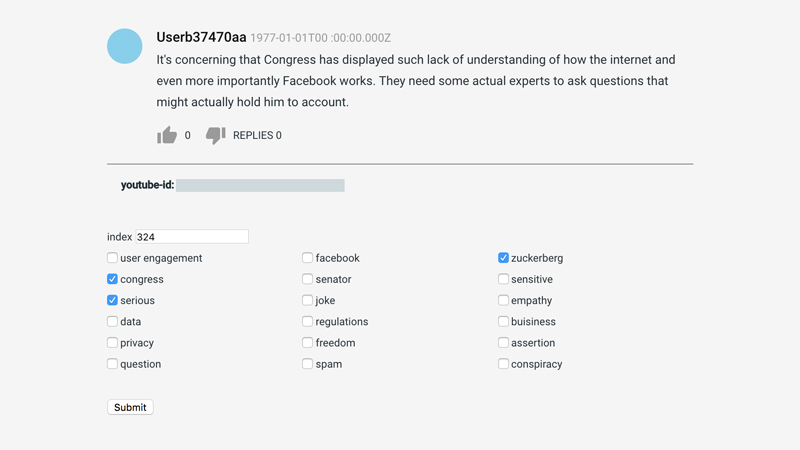
Sticking with the theme of the Facebook and Cambridge Analytica scandal it was decided that an analysis of YouTube comments threads from videos broadcasting the US congressional of Mark Zuckerberg would be performed. These were collected using YouTubes Data API equating to roughly 2000 threads across 2 videos (hJdxOqnCNp8, 6ValJMOpt7s). These included the possibilities of replies within each. Using these sought to provide evidence that mapped discussions within the topic. Though YouTube comments can be just as inflammatory as Twitter posts their visibility poses more opportunities for the responses of other users over a more sustained period. Because of less restrictions on content length, sustained and lengthy arguments are possible through this medium. As threads contain responses from a variety of different actors, interactions can be graphed effectively. This is to be considered in a developing framework.
Abandonment
Ultimately, to make this process worthwhile, it seemed there needed to be a longer and more in-depth period of reflection made prior to analysing the content. Developing a framework in which to apply to the data was obviously the most time-consuming part. A general strategy of its application was to build an interface that aimed to optimise analysis by automating things like conditional logic (e.g. discussions of data regulation -> political talk) as well as any tasks that can be done by machines (e.g. constructing conversation graphs). In this process, there was a tendency to design the interface server in the most generalizable way possible which was another thing taking up too much time.
Conclusion
This process wasn’t essential for the investigation of the Facebook and Cambridge Analytica scandal instead it was something of interest. It sought to address concerns that tools research being used were having too much of a formative effect on the types of investigations that were being made – I.e. only analysis that machines can perform well. Though not complete the word done has provided a starting point that may go on to be used in another project.
References
- Graham, T. 2008. Needle in a Haystack. Javanost – The Public. 15(2). Pp.17-36.
- Zamith, R. and Lewis, S. 2015. Content Analysis and the Algorithmic Coder: What Computational Social Science Means for Traditional Modes of Media Analysis. The ANNALS of the American Academy of Political and Social Science. [Online]. 659(1). pp.307-318. Available from: http://journals.sagepub.com/doi/abs/10.1177/0002716215570576#articleCitationDownloadContainer