Finding civic discussions on Twitter
As explored in the previous article, academic literature has conceived of citizenship in many ways, differentiating its dimensions and discourse. This article will seek examples of these conceptions in practice, exploring their possible manifestation within the online social platform Twitter. Computational methods will be used to explore a small dataset of around 150,000 tweets collected over two separate time periods. Trying to uncover types of discussions that occur within the site will serve as the starting point for further investigations.
Introduction
This current articles investigation is focused on the thematic content of civic communication. It is starting from the position that individuals do use Twitter to engage in civic and political communication.
Why Twitter?
Twitter poses a sensible point of departure for an exploration of citizenship online for several reasons. With many active users generating large amounts of semi-structured data, the site has become a common target for social research. The platforms configuration facilitates not only the short expression of public sentiment but also provides structures helpful for its aggregation and categorization in the form of hashtags, geolocations, mentions, etc. Also, aided by well documented API’s and a variety of existing tools, it has become an easily available resource for all kinds of researchers.
Whether Twitter is the best place to look for examples of citizenship in online public discourse is not the question posed here. Rather, how can civic communication be traced and linked to theory and what methodologies could be appropriate for uncovering it?
Methodology
Data Collection
Using Twitter’s streaming API, two separate datasets were constructed by aggregating tweets filtering for the keywords 'citizen', 'citizenship' in real-time. This was done using a custom Go program which ran between 25/1/2018 - 31/1/2018 (S1) and then again between 22/2/2018 – 02/3/2018 (S2). The given query terms were chosen provide a literal, open-ended and naïve entry point to the topic. This was repeated twice to try find more persistant themes within the data. The streaming API’s documentation states that this will return roughly 1% of all tweets subject to the filter terms provided. This approach was preferable to the also available search API which provides limited access to past tweets subject to certain forms of curation. Other media communication scholars such as have Carolin Gerlitz, Bernhard Rieder have also recommended the more random sampling provided by the streaming API (2013).
Before moving to analysis pre-processing was performed, removing non-English tweets, splitting into training and test sets, removing stop words, word stemming and other filters. After this step each set contained roughly 65,000 tweets with features such as, hashtags, user mentions, sentiment analysis, timestamps (s2 only), and the tweet text itself.
Analytical Methods
The main objective of investigating this data is to quickly find discursive topics and themes that give insight to the types civic conversations that may occur on Twitter. Because of this, investigations focused on the occurrences, and co-occurrences of words and terms within the data.
To help ascertain the content of the tweets, topic extraction with Non-Negative Matrix Factorization and Latent Dirichlet Allocation was experimented with. Latent Dirichlet Allocation (LDA) is generative probabilistic model well suited for textual data summarisation (Blei, D.M., Ng, A.Y. and Jordan, M.I. 2003. p.993). What this essentially does is iteratively generate random groups of words from the dataset testing the probability of co-occurrences of terms, optimizing for a specific number of iterations trying to increase the probabilities of terms existing within each set. In the process this generates what resembles real topics in the data (2003). Though implementation varies, Non-negative Matrix Factorization works similarly to the LDA model using the Kullback-Leibler approach. Some online have argued that in some cases NNF can produce more meaningful results on smaller datasets. These models were implemented in the python programing language using the open source library Scikit-Learn. This package has also been used to produce TF-IDF scorings and other analysis tools.
Source code for all the aforementioned techniques, including Go collection script, Python pre-processing script, and analyses within Jupyter Notebooks are available via GitHub.
Analysis
Per dataset, a dominant topic can be found relating to events in American politics that occurred during their collection. The first (S1) related to the Tump administrations planned cancelation of the Deferred Action for Childhood Arrivals (DACA). The second (S2) presents recurrent debates associated with gun control laws following the Florida mass shooting and the response by the NRA. S1 was highly focused on the topic of DACA with all generated topic samples appearing to be a subset of this main topic. S2 presents greater topic variance, evidencing some tweets focused on DACA as well as the debates on gun control.
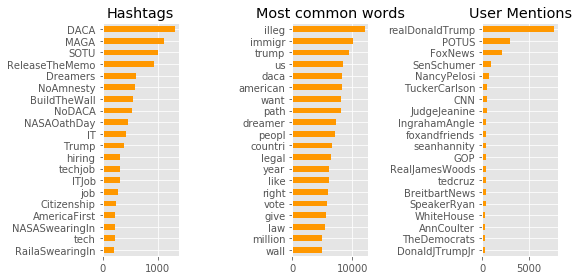
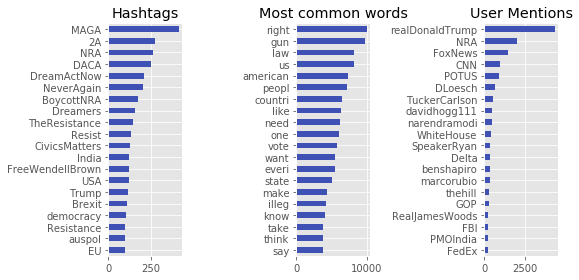
S1, S2 Count frequencies per feature:
Using a purely count based method we can see these themes in the form of user generated hashtags, and most-common words in both dataset (S1= █ amber, S2= █ blue). In the case of hashtags, we can probably make some clear inferences via the intentions of users to include them. However, the word frequency significance is more convoluted and does not provide additional context to the vocabulary usage. Even though stop words have been removed we just literally just seeing the most common but not necessarily the most important words across the dataset.
S1, S2 TF-IDF scores:
Using TF-IDF weighting on n-grams we can expand on the information that being communicated. The charts below are showing the top TF-IDF scores for each tweet summed across the dataset.
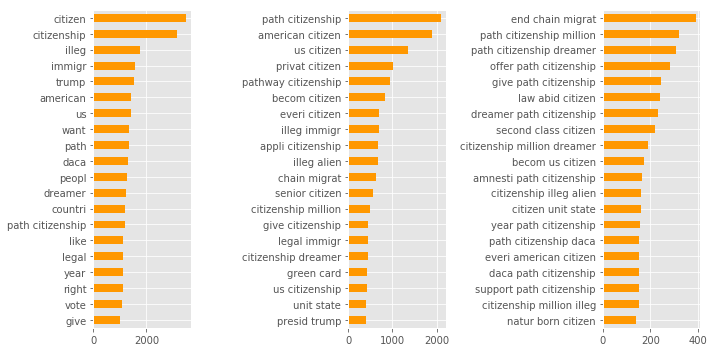
S1 exhibits the trigram 'end chain migration' as the most significant word sequence, this is perhaps the most clearly stated sentiment of this dataset. Other trigrams such as 'give path citizenship', 'offer path citizenship' and 'support path citizenship' could provide evidence of counter positions however these could more naturally be prefixed with negations. As a recent New York Times article has argued, ‘chain migration’ is a loaded term that evidences a certain position on immigration.
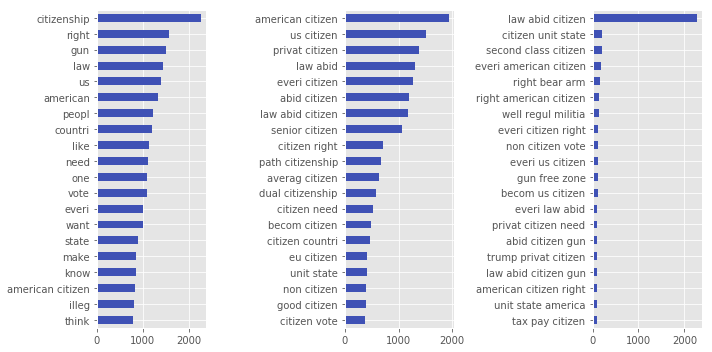
S2 shows the trigram law abiding citizen massively out scoring all other terms. This could be attributed to the construction of the dataset, but following debates online it does seem like a recurrent form of argument. The mention of the law abiding citizen was also present in S1, just not as pronounced.
S2 Topic Modeling
NNF results for S2 are given here showing clustering’s of terms within the data. These have been qualitatively annotated as can be seen below. In both dataset, similar topics to T1 and T4 were present. Through the lens of civic theory these present the kinds of citizenship-as-desirable-activity and citizenship-as-legal-status described by Kymlicka, Norman (1994) and others. The first seems to be referent to more global contexts the second to more national. Political communication professor Stephen Coleman has argued that currently these two ideas represent a recurrent divide in the perceptions of how politics should be done an organised across the globe (2017), something that seems agreeable in the context of the evidence here.
| T | Qualitative Description | Representations of Topics Generated by NMF Model |
|---|---|---|
| 1 | General sentiments about citizenship in a global context. | citizenship, us, want, peopl, like, countri, one, year, work, make, know, us citizen, time, think, say, take, need, live, way, give, immigr, use, nation, even, see, good, thing, still, right, legal, help, world, tri, govern, well, come, illeg, without, support, state |
| 2 | US gun control. emphasis on Law abiding citizens | law, law abid, law abid citizen, abid, abid citizen, gun, crimin, enforc, law enforc, weapon, shoot, gun law, owner, protect, nra, mental, citizen gun, gun owner, away, shooter, firearm, kill, murder, check, school, take gun, own, problem, polic, background, purchas, ban, crime, mass, background check, carri, buy, rifl, everi law, gun control |
| 3 | US gun control debate | gun, everi, weapon, need, right, everi citizen, arm, protect, nra, use, one, peopl, stop, polic, militari, kill, shoot, averag, take, rifl, think, school, assault, amend, govern, averag citizen, citizen need, respons, war, reason, well, train, like, teacher, militia, good, defend, ban, time, say |
| 4 | General Citizen legal rights in various contexts | right, american, vote, american citizen, state, illeg, elect, unit, constitut, unit state, non, voter, citizen right, non citizen, protect, citizen vote, legal, democrat, everi, polit, law, regist, support, right citizen, democraci, presid, feder, illeg alien, regist vote, parti, america, wrong, must, usa, alien, violat, requir, russian, proof, right vote |
In both cases the discourse is broadly centred on the rights to have rights – the right to U.S. citizenship and the right to own a fire-arm. These are both discussions concerning the legal policies of these rights, arguably we can see that civic virtue has been often used as the basis for these rights. This interplay of civic law and civic virtue within the dataset de-compartmentalises these dimensions of civic theory. Here they are used in a reciprocal manor. Lawfulness may be used to argue civic virtue and therefore the right to other lawful rights. In the context of gun control (S2) this may be the position that law abiding citizens should not have their 2nd Amendment taken away. In the context of immigration (S1), an illegal immigrant may be able to claim other virtues, but technically speaking they cannot be a law-abiding citizen, due to their legal status within the nation state. This is just honing in on one aspect of the data for instance we can also see arguments of civic responsibility and needs within both debates.
Conclusion
As we have seen here the data collected has evidenced engagement in civic issues, particularly regarding the implementation of US law relating to the rights of citizens. However due to the episodic nature of the data, more generalised methods for defining and investigating civic issues are not presented. Epistemological questions have arisen in ways of knowing and understanding data in aggregate form, further investigations will take place along these lines. There is also interest in how to engage with different subsets of narratives in a more fluid manor than simply tracking specific terms. These issues will be explored in future articles.
References
- Blei, D.M., Ng, A.Y. and Jordan, M.I. 2003. Latent Dirichlet Allocation. Journal of Machine Learning Research. [Online]. 3(1). pp.993-1022. [Accessed 17 March 2018]. Available from: http://www.jmlr.org/papers/volume3/blei03a/blei03a.pdf
- Coleman, S. 2017. Can the Internet Strengthen Democracy? UK: Polity Press. google books
- Gerlitz, C. and Rieder, B. 2013. Mining One Percent of Twitter: Collections, Baselines, Sampling. M/C Journal. [Online]. 16(2). [Accessed 17 March 2018]. Available from: http://journal.media-culture.org.au/index.php/mcjournal/article/view/620
- Kymlicka, W. and Norman, W. 1994. Return of the Citizen: A Survey of Recent Work on Citizenship Theory. Ethics. [Online]. 104(2), pp. 352-381. [Accessed 3 January 2018]. Available from: http://www.jstor.org/stable/2381582
- http://scikit-learn.org/0.18/auto_examples/applications/topics_extraction_with_nmf_lda.html