Mark Zuckerberg personality insights
Considering the attention drawn to data privacy after the recent Facebook and Cambridge Analytica fiasco, it seems relevant to explore some available tools for gathering insights on online publics. This article will experiment with IBM’s off the shelf personality insights tool to example the kinds of features that can be constructed from user data. It will use Mark Zuckerberg’s response to Cambridge Analytica’s apparent miss-use of Facebook data as a sample source.
Introduction
The combination of modern psychology, big data and deep learning has opened possibilities for advertisers, political campaigns and others to personally target individuals on a massive scale. Research as such done by Michal Kosinski and others has continued to show a variety ways social media data can be used to predict personal attributes such as sexual orientation (Wang, Y. and Kosinski, M. 2018), age, gender and personality (more citations?). Though Cambridge Analytica’s impact on the 2016 U.S. election may be overstated, questions still arise to the effects of micro targeting can have on the functioning of democracies and to what extent have user’s consented to this subjection.
In this article IBM’s services are used as an example to demonstrate some generic models for creating insights from personal data. Mark Zuckerberg’s recent PR response posted publically on Facebook is given as example that will serve as the basis for the personality insights. Here it the sample text for your reference, if you would like to read it:
Beyond being a bit of fun, the example here aims to show how cheaply available insight tools are becoming whilst questioning there increasing use in society.
Natural Language Understanding
Before going on to the results of the personality insights we can also quickly use IBM’s Natural Language Understanding API to get a brief outline of the document. Copy and pasting the Marks post into the demo site we get as follows:

As well as summarising the object of the text sample, we can see I want to share as key the subject/action. This is describing the sematic roles of the document, what about the emotional content?

Interestingly the emotion is put forward as mixture of joy and sadness. Perhaps sadness because of the news, by optimistically joyful about prospects of your future with Facebook 💁.
Personality Insights
Personality insights can arguably be used to gauge what kind of consumer you will be, the kind of products you will be more likely to buy and more increasingly what political messages may sway you. IBM’s personality insights demo page describes the service as follows:
Gain insight into how and why people think, act, and feel the way they do. This service applies linguistic analytics and personality theory to infer attributes from a person’s unstructured text.
Again, just copy and pasting Marks post into the demo yields a range of results, the first thing we are greeted by is high level summary shown below:
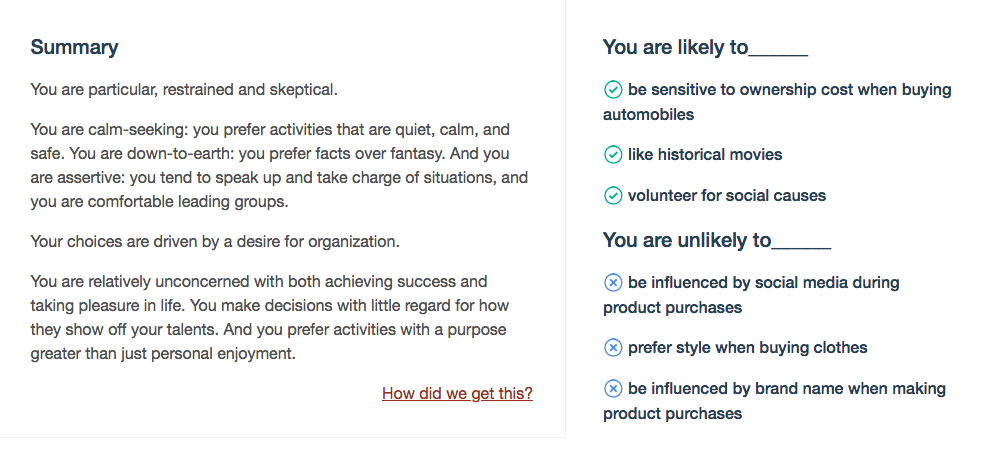
I always thought Mark was unlikely to be influenced by social media during product purchases but how did the application know that? Well according the what is described in the science of the services, specific personality profiles that are constructed suggest certain consumer behaviour. We can consider what this means a bit more with some of the other data the demo provides.
Personality, Needs, Values
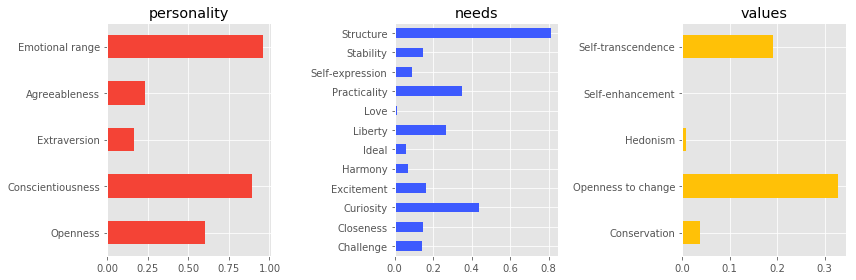
Diving into some of the data we see personality represented in three main categories:
Big Five model: This is one of the most widely studied personality models in clinical psychology. It describes a person in terms of openness, conscientiousness, extraversion, agreeableness, and neuroticism - It is sometimes referred to as the OCEAN model. Here neuroticism has been renamed in the service as emotional range as it was thought more ‘generally applicable’ (IBM Cloud Docs, 2017).
Needs: ‘The twelve categories of needs that are reported by the service are described in marketing literature as desires that a person hopes to fulfil when considering a product or service’ (IBM Cloud Docs, 2017). (They are referring to: Kotler, P. and Armstrong, G. 2013. Principles of Marketing; Ford, K. 2005. Brands Laid Bare: Using Market Research for Evidence-Based Brand Management.)
Values: ‘computes the five basic human values proposed by Schwartz and validated in more than twenty countries’ (IBM Cloud Docs, 2017).
You can see the results of these fields below.
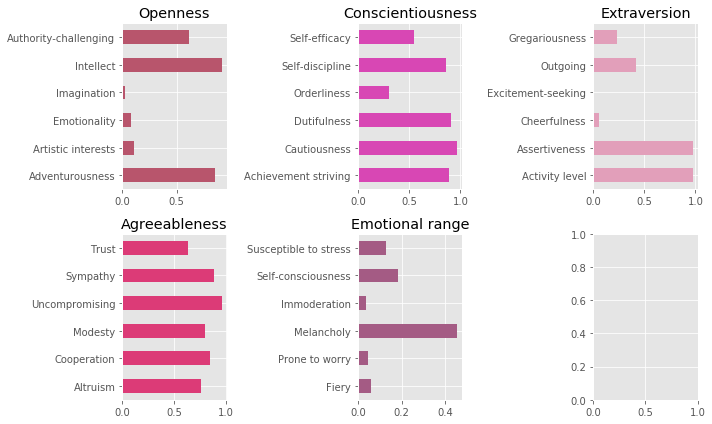
A more detailed look at the Big Five
The service goes on to break-down the Big Five model into 10 features each making it 50 feature model. Because the more features the better right.
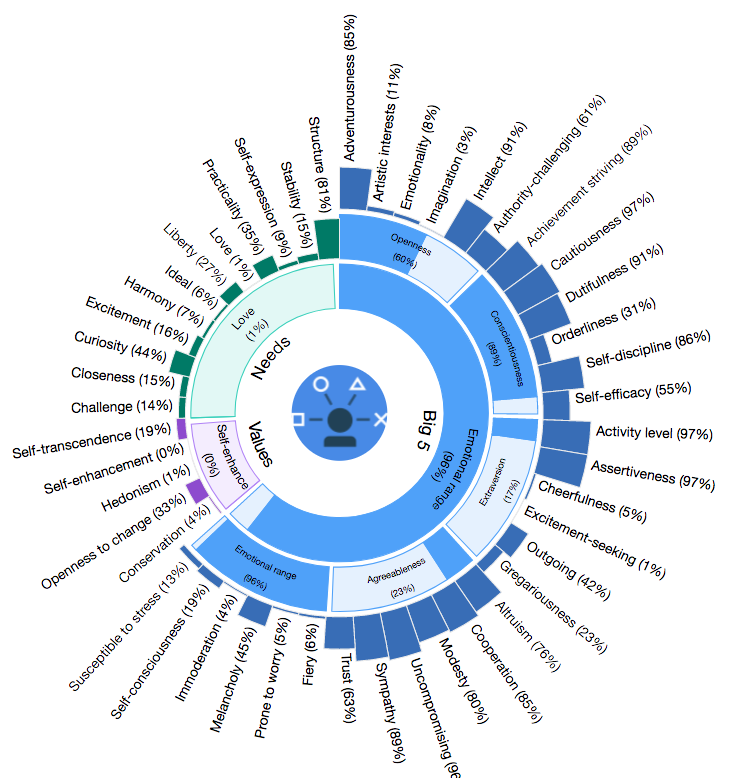
If my graphs aren’t nice enough for you here’s a nice 👌’sun burst’ visualisation of all the data shown above generated by the site.
Consumer Preferences
As stated previously inferences can be made about the kinds of choices individuals are likely to make based on specific personality traits. Using the features described above, models have been created by IBM to fit specific consumption preferences to specific personality types. Though not shown overtly on the demo page there is the option to download a JSON file with all the generic tests carried out. These can be listed as follows:
Shopping
- Likely to be sensitive to ownership cost when buying automobiles: 1.
- Likely to prefer safety when buying automobiles: 0.
- Likely to prefer quality when buying clothes: 1.
- Likely to prefer style when buying clothes: 0.
- Likely to prefer comfort when buying clothes: 1.
- Likely to be influenced by brand name when making product purchases: 0.
- Likely to be influenced by product utility when making product purchases: 1.
- Likely to be influenced by online ads when making product purchases: 0.
- Likely to be influenced by social media when making product purchases: 0.
- Likely to be influenced by family when making product purchases: 0.
- Likely to indulge in spur of the moment purchases: 0.
- Likely to prefer using credit cards for shopping: 1.
Health and activity
- Likely to eat out frequently: 0.
- Likely to have a gym membership: 0.
- Likely to like outdoor activities: 1.
Environmental concern
- Likely to be concerned about the environment: 1.
Entrepreneurship
- Likely to consider starting a business in next few years: 0.5.
Movie
- Likely to like romance movies: 0.
- Likely to like adventure movies: 1.
- Likely to like horror movies: 0.
- Likely to like musical movies: 0.
- Likely to like historical movies: 1.
- Likely to like science-fiction movies: 1.
- Likely to like war movies: 1.
- Likely to like drama movies: 0.
- Likely to like action movies: 1.
- Likely to like documentary movies: 1.
Music
- Likely to like rap music: 0.
- Likely to like country music: 0.5.
- Likely to like R&B music: 0.5.
- Likely to like hip hop music: 0.
- Likely to attend live musical events: 0.
- Likely to have experience playing music: 0.
- Likely to like Latin music: 1.
- Likely to like rock music: 1.
- Likely to like classical music: 1.
Reading
- Likely to read often: 1.
- Likely to read entertainment magazines: 0.
- Likely to read non-fiction books: 1.
- Likely to read financial investment books: 1.
- Likely to read autobiographical books: 0.
Volunteering
- Likely to volunteer for social causes: 1.
Some of these may seem silly, but in a real-world scenario you would create your own models to cater for your own specific needs. This part isn’t as cheap an endeavour and without existing data you would need to gather your own data for your needs.
Conclusion
How accurate is this?
Short answer: In this example, not at all.
As the demo website states the sample is far too short to create an accurate analysis. However, say given a complete user profile the results are argued to become more effective. I found a few references to horoscopes in online discussions concerning the service (Quora).
Looking for other examples of this kind of service to get a comparison, the website created by Cambridge University https://applymagicsauce.com/ is probably the most similar available online. However, I didn’t try that one out in the end because it wanted access to my social media data.
With this kind of service the accuracy will always be hard to measure. Even though it is relying on numerical computations we are still receiving qualitative results. For example, agreeableness is much more a relative measure than a count of objects. Using tried and tested psychological frameworks means the service probably does have some merit however.
Final thoughts
Whether this is an accurate description of Mark’s personality or even the text is not the argument. This example was used to start to think about how tools trying to ascertain behavioural insights are integrating with society. The demo page emphasises that a represented sample be used. A person’s social media data tends to be thought of as a representative perhaps for its capacity for eclectic expression. This service and those like it will always be an assessment of a representation of a person not of them themselves. The affordances of these services to those seeking insights depend on its accuracy but to those who are the subject of inquiry this is not always the case. For example, in the field of recruitment, services like that provided by hirevue use machine learning to gain insights on candidates scoring them via various metrics. Here, for the subject of inquiry accuracy is less important than a favourable outcome (i.e. getting the job). In this way, there is possibility for these tools to shape the behaviour of individuals. What happens when this becomes more widely used in society for decision making processes and is also further democratised? This could make for interesting future inquiry especially with regards to more civic matters.
References
- Wang, Y. and Kosinski, M. 2018. Deep neural networks are more accurate than humans at detecting sexual orientation from facial images. Journal of Personality and Social Psychology. [Online]. [Accessed 22 March 2018]. 114(2), pp.246-257. Available from: https://psyarxiv.com/hv28a/
- IBM Cloud Docs, 2017. The science behind the service. [Online]. [Accessed 22 March 2018]. Available from: https://console.bluemix.net/docs/services/personality-insights/science.html#science
- IBM Watson Developer Cloud, 2017. Personality Insights. [Online]. [Accessed 22 March 2018]. Available from: https://personality-insights-demo.ng.bluemix.net/
Other resources
- IBM research reference list
- Costa, P., and McCrae. R. 2008. Revised NEO Personality Inventory (NEO-PI-R) and NEO Five-Factor Inventory (NEO-FFI) Manual. Odessa, FL: Psychological Assessment Resources (1992). Available from: https://www.researchgate.net/publication/285086638_The_revised_NEO_personality_inventory_NEO-PI-R
- Apply Magic Sauce personality insight app
- Michal Kosinski - The End of Privacy, Keynote at CeBIT’17
- http://www.michalkosinski.com/home/publications
- The Power of Big Data and Psychographics