Data, politics and democracy part 3: Analysis of The Guardian's content
Here will detail investigations into content created by the Guardian, a key player in the dissemination of the Facebook/Cambridge Analytica story. It will use computational methods such as keyword extraction, also making comparisons with the previously collected data from Twitter.
Strategy
Seeing that The Guardian was one of the main news organisations to break the initial story, arguably it is relevant to look at patterns within their coverage. Acting as The Fourth Estate, it’s common to assume that, news organisations are expected to hold governments and other public entities to account, how has this been done here? Whilst additionally taking into consideration the results of the Twitter data analysis’, comparisons between the two content types will be made. As part of a series, a picture is gradually being built up from a variety of different perspectives. Later this information will be used to discuss the content of the two media types, and the topic more generally.
Making use of the Guardians Open Platform API, all the articles between the 17/03/2018 - 24/03/2018 were collected for analysis. This collection period starts on the date of the initial story and finishes when the previously sampled Twitter data ends its collection span. Symmetrical query terms were likewise used, here translated in terms of the Guardians search API, this is literally written as facebookANDcambridge analytica. The content collected was then analysed using a variety of different methods, looking at both manual and machine generated structures within the data. Keywords were generated automatically using the RAKE algorithm, other approaches like TF-IDF scores over n-grams, and topic generation as discussed in previous articles were also utilised.
RAKE algorithm
Presented in Rose, S. Engel, D. Cramer, N. and Cowley, W. (2010), the Rapid Automatic Keyword Extraction (RAKE) algorithm does as the title describes, generating keyword phrases from individual documents – ideally short texts like abstracts. A characteristic of this algorithm is that it weights longer sequences more heavily, resulting in more greedy results. More details about how this is implemented can be found in the methods page of this blog.
To depict keywords across the whole corpora, a method described in authors paper for finding the most ‘essential’ terms was used conjunctively. The calculation of this can be summarised as follows:
Where the edf (extraction document frequency) is the number of documents the candidate was extracted from as a keyword and rdf (reference document frequency) is the number of times a candidate appeared across the collection. With this approach, perhaps we will be able to get an alternative but reasonable portrayal of the keywords within these articles.
Due to its relative simplicity, the RAKE algorithm and other related functions were implemented as needed here in the Python programming language and can be found in the text_tools section of this blogs GitHub repository (digitalcitizens/rake).
Analysis
Article Keywords
Manually generated
Looking at the human generated keywords tells about not only about the articles but also the internal practices of the organisation. Through being the query terms given, Cambridge Analytica and Facebook naturally top the chart, most of the top items are meta keywords that describe overarching collections of content like Technology or UK news. The categorisation of news types geographically can tell us more about the priorities of the content producers (e.g. ‘US news’). This can be described here as UK news > World news > US news. Because of this, although the US 2016 elections where a key part of the topic, we are more likely to see British issues like Brexit reflected.
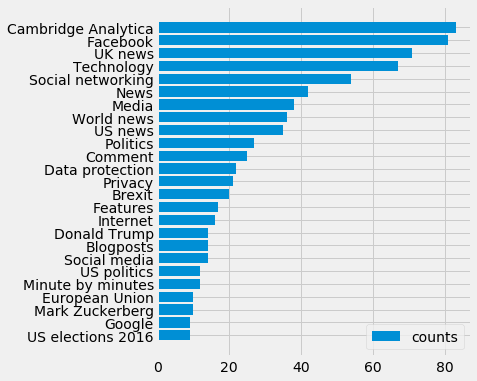
With knowledge of what this data concerns we could use these tags to inversely query content over a longer period within the paper. Possible topics of interest can be listed as, Data protection, privacy, social media. Seeing how these topics have evolved over time might be an interesting line to follow in establishing the publishing patterns. This will be discussed at a later point in this article.
RAKE results
Comparing the RAKE key phrases with the human generated ones, the differences in style are apparent. The human keywords provide quite clear and considered meta data whose core function it to group content systematically. Here, though following qualitatively similar topics, we find structure in the natural language of the news reporters. For such a simple approach, it does appear to give good results. One noticeable caveat its failure to capture single word key phrases well – questionably Brexit is missing here. We can see also the tendency for it to be greedy and present longer phrases such as 50m Facebook profiles over more simply Facebook.
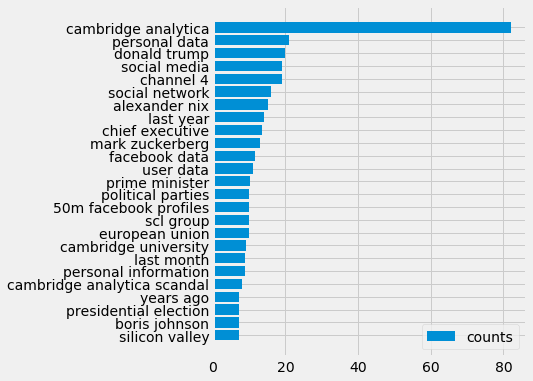
Questions also arose in how much of the input text the algorithm should be applied to. Though best use cases for it are often described as shorter texts, like abstracts, the characteristics of the standfirst content used to describe articles had a tendency to cram words together without using stop words often. A purely constructed example of this might be: Canadian Whistle blower breaks Cambridge Analytica data scandal story. As this to many standards doesn’t contain any stop words, it would be a single keyword candidate, ultimately leading to unhelpful and long results. Because of this, full articles were given as inputs instead which performed more successfully.
Comparisons with Twitter data
Generating TF-IDF scores for unigrams and bigrams across both datasets, comparisons of the content can be made ( █ The Guardian, █ Twitter). With similar pre-processing steps being taken with each, an initial observation finds differences in structure and consistency. Thus, the twitter data has far more low information words and media specific language (e.g. retweeted). Query terms within the Twitter data seem to be far more impactful to the scores generated. As an item of content only needs one occurrence of a query term to be collected, the ratio of query terms to non-query terms is obviously higher in shorter texts. A possible way to combat this might be to normalise their scores based on content length, though this has not been applied here.
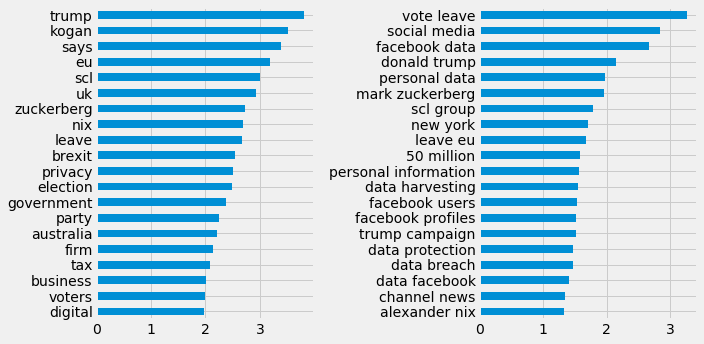
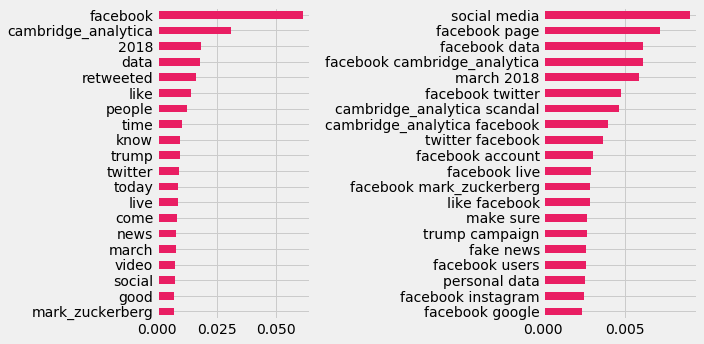
As noted previously the Guardian content is more concerned with UK affairs, e.g. the vote leave campaign. Perhaps having more American users, Brexit related affairs do not show up at all within the Twitter rankings displayed. Though there might not have been time for stories to circulate and articles here do not represent total media coverage, one of the key actors Aleksandr Kogan seems to not have received as much attention from Twitter. To some extent we could argue that the main issue is the general social practices facilitated by Facebook between data and political organisations. Facebook Is the only actor here that has a consistent relationship with society, and naturally should receive the most attention.
Though better representations could have been achieved with the Twitter results it was decided here not to pursue even more cleaning steps. As noted before, this dataset was especially messy. Working with the Guardian articles, though needing some pre-processing steps was a real breath of fresh air.
Time series data over the last 8 years
Working with some of the top keywords generated by the paper, additional data was collected from the Guardians API. This queried posts between 2010 and the present. A times-series of articles per query can be detailed below.
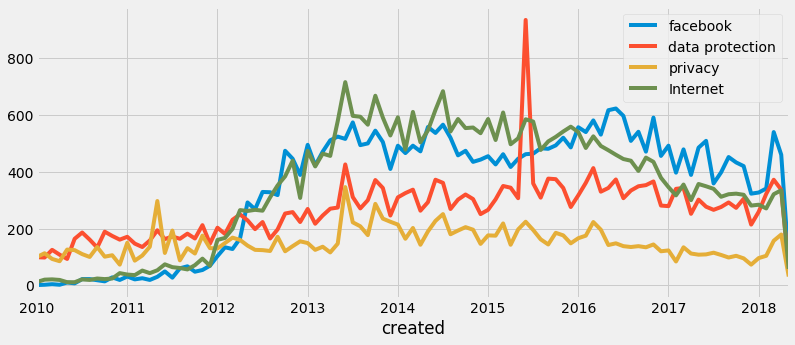
Using the tiles of the articles to determine subtopics within the query the most related bi-grams can also be shown below. Only privacy and data protection we displayed as the others were more generalised and of less interest.
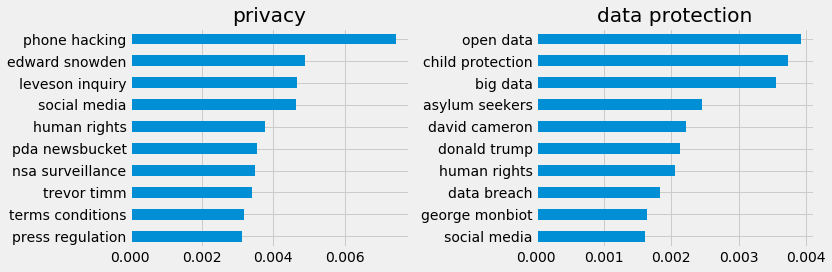
It seems ‘phone hacking’ and ‘Edward Snowden’ are top of the list. Looking back at the time series data there only seems to be a small peak in 2011 at the time of the phone hacking scandal whilst around the time of the Snowden leak there seems to be a greater peak in data protection, privacy and the internet. Facebook seems to have got most attention mid 2016 then peeked up again recently. It’s unclear to my knowledge what happened in 2015 regarding data protection, but it seems like someone must have had a wild month or two. Another point of interest is that since 2016 Facebook maintained more coverage that the Internet more generally, something that feeds into the narrative that the internet is becoming merely the walled gardens of the giant social media platforms.
Read Next: Part 4: Reflections
References
- Rose, S., Engel, D., Cramer, N., and Cowley, W. 2010. Automatic Keyword Extraction from Individual Documents. In: Berry, M.W. and Kogan, J. ed. Text Mining: Applications and Theory. UK: Wiley-Blackwell. pp.1-20. Also available online